Blog de Zscaler
Reciba en su bandeja de entrada las últimas actualizaciones del blog de Zscaler
Suscríbase
¿Entiende sus SLA? Guía para desmitificar los SLA de seguridad en la nube
¿Por qué los SLA?
Los SLA o acuerdos de nivel de servicio (en el contexto de este blog) son la expresión de confianza de un proveedor de seguridad en la nube en su capacidad para ofrecer un servicio resistente, escalable y de alto rendimiento. Los SLA se volvieron más comunes a medida que las soluciones SaaS se hicieron más populares, y proporcionaban a las organizaciones garantías sobre sus niveles de servicio, como el rendimiento y la disponibilidad, en un gran grupo de recursos compartidos. Aunque los SLA tienden a ser un objetivo principal para los abogados, todas las partes interesadas en una decisión de compra deben comprender el SLA de un proveedor para:
- Identificar los impactos en la actividad empresarial de la fiabilidad, la velocidad y la experiencia general del usuario asociada al servicio.
- Cuantificar el riesgo comprendiendo qué exclusiones existen en su acuerdo.
- Diferenciar entre líderes e innovadores del sector frente a otros vendedores que utilizan palabrería inteligente para crear una ilusión de calidad en los acuerdos de nivel de servicio.
En esta publicación, analizaremos los SLA de los proveedores de seguridad en la nube, de Zscaler y otros, a fin de:
- Encontrar el ingrediente secreto de Zscaler para los SLA líderes del sector
- Descubrir y analizar los componentes más importantes de los acuerdos de nivel de servicio (SLA), con un análisis específico del SLA de latencia del proxy
- Dotarle de criterios de evaluación para diferenciar los acuerdos de nivel de servicio líderes en el sector de los acuerdos de nivel de servicio de otros proveedores, que con demasiada frecuencia están plagados de exclusiones que desvirtúan el objetivo del acuerdo de nivel de servicio.
El enfoque de Zscaler sobre los SLA: identificar el ingrediente secreto
Simple y llanamente: el ingrediente secreto de los SLA líderes en el sector es una nube de seguridad líder en el sector. No puede pasar directamente a los SLA tener un modo de respaldarlos.
En Zscaler, el respaldo de nuestros acuerdos de nivel de servicio líderes en el sector es el resultado de más de una década de ser pioneros, construir y poner en funcionamiento la mayor nube de seguridad del mundo diseñada para asegurar el tráfico de misión crítica. Hemos visto que muchos proveedores intentan replicar nuestro enfoque, enmascarando su falta de diferenciación técnica en los SLA, que parecen buenos en la superficie, pero son engañosos en la práctica.
Estos son algunos de los principales atributos de otros proveedores:
Proveedores de productos puntuales CASB que intentan expandirse a nuevos mercados:
- Plataforma diseñada para tareas simples como el análisis fuera de banda de aplicaciones SaaS utilizando API REST en lugar de procesar el tráfico de misión crítica a velocidad de línea, lo cual requiere un ADN y enfoque muy diferentes.
- Estrategia de producto centrada en anunciar funciones de casilla de verificación antes de los informes de analista importantes (es decir, Gartner MQ) en lugar de descubrir y resolver problemas únicos de los clientes.
- Arquitecturas basadas en el proyecto de código abierto proxy Squid, que tiene una larga historia de errores de adaptación.
Proveedores de hardware heredado que intentan seguir manteniendo su importancia:
- Reutilizando dispositivos virtuales de un solo usuario en IaaS (es decir, GCP, AWS) con centros de datos informáticos limitados, un modelo de responsabilidad compartida y una disponibilidad poco fiable.
- Encadenando servicios mediante la incorporación de servicios existentes y nuevos que introducen complejidad y latencia con cada capacidad adicional.
- Actualizaciones irregulares del servicio y del sistema operativo para los cortafuegos VM (por ejemplo, 6-9 meses para que las actualizaciones del sistema operativo migren de cortafuegos físicos a cortafuegos de máquinas virtuales alojados en la nube pública).
Estos enfoques han demostrado tener limitaciones significativas para ofrecer un servicio de calidad y en los SLA resultantes. Explicaremos estas limitaciones con más detalle a continuación.
Orgullosos de mostrar nuestra escala
Al evaluar los SLA de un proveedor, usted, en esencia, evalúa la fortaleza de su plataforma en la nube. Sin datos accesibles públicamente sobre la escala y el rendimiento, ¿cómo puede evaluar realmente la plataforma y los SLA resultantes? Zscaler es el único proveedor del sector que comparte públicamente los datos para respaldar nuestras afirmaciones sobre escala y rendimiento.
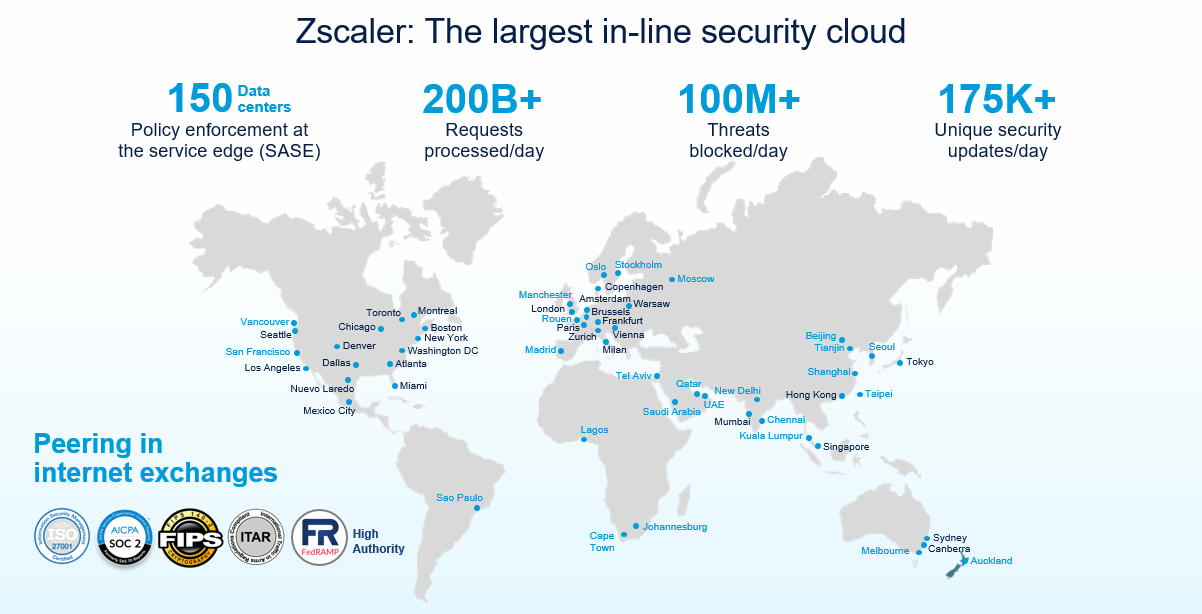
La huella global de Zscaler: 100 % de centros de datos de computación (sin rampas o vPoPs)
Estamos tan seguros de nuestras afirmaciones sobre la escala que queremos que lo vea usted mismo, en cualquier momento, con datos en tiempo real. Consulte el panel de actividad de la nube de Zscaler para ver estas métricas actualizadas.
Ideas para reflexionar:
¿Por qué ningún otro proveedor proporciona datos públicos o métricas sobre su escala o cómo funciona su nube? (Consejo profesional: una foto de un coche de carreras para simbolizar la velocidad NO cuenta como prueba).
Los SLA de Zscaler: alta disponibilidad, seguridad superior y velocidad ultrarrápida
Esa es la esencia de los SLA de Zscaler Internet Access (ZIA) tal y como se describe en nuestra hoja de producto. Operar la nube de seguridad líder del sector exige SLA líderes del sector:
1. SLA de alta disponibilidad (fácil de usar)
En general, aquí es donde los proveedores luchan por el número de nueves (verá escrito “5 nueves", lo que comúnmente significa un 99,999 % de disponibilidad). Cuantos más nueves, mayor será el compromiso de disponibilidad. Por ejemplo, con un 99,9 % de disponibilidad, un proveedor garantiza que su servicio estará fuera de servicio durante no más de 525 minutos en un año: (1-99,9 %) x 525 600 (525 600 es el número de minutos en un año). Un proveedor con cinco nueves, o 99,999 %, se comprometerá a menos de 6 minutos de tiempo de inactividad por año.
Si lee atentamente nuestros acuerdos de nivel de servicio, se dará cuenta de que Zscaler ofrece un acuerdo innovador basado en el porcentaje de transacciones perdidas como resultado del tiempo de inactividad o la lentitud en lugar del porcentaje de tiempo que el servicio no estuvo disponible. Este SLA fácil de usar se alinea estrechamente con el impacto comercial real del tiempo de inactividad e incluso devuelve créditos cuando el servicio está 100 % disponible, pero el cliente está experimentando una desaceleración debido a una congestión inesperada.
Idea para reflexionar:
Si sus transacciones cayeron un 20 por ciento debido a la congestión, ¿su proveedor afirmaría que el servicio estaba disponible en un 100 por ciento?
Aquí es donde los proveedores de realojamiento, que ejecutan sus máquinas virtuales heredadas de un solo usuario en IaaS, tienen más dificultades debido a la falta de control y a la imprevisibilidad de la infraestructura subyacente. Es bastante común ver a estos proveedores llenar sus SLA con una larga lista de exclusiones, que contrarrestan el propósito del SLA.
En este ejemplo, un proveedor de NGFW heredado excluye actualizaciones no planificadas del SLA, lo que lo hace inútil:

Idea para reflexionar:
Si la nube se cae inesperadamente y sin previo aviso, no cuenta como tiempo de inactividad, ¿entonces qué lo hace? ¿No es esa la definición de tiempo de inactividad?
En otro ejemplo, el mismo proveedor de NGFW heredado excluye los eventos de escala de su SLA:

Idea para reflexionar:
¿No es un objetivo primordial de los servicios en la nube eliminar la sobrecarga y la ansiedad que supone el escalamiento?
2. El SLA de captura de virus 100 % conocidos (seguridad superior)
Un proxy de hiperescala no solo debe ofrecer una experiencia de usuario increíblemente rápida, sino también una seguridad superior sin atajos. Si solo necesitáramos pasar paquetes del punto A al B sin analizar, podríamos haber ofrecido una latencia de 0 ms, pero con una seguridad terrible. El SLA de captura de virus conocidos es exclusivo del sector y una prioridad del sector que, de nuevo, traduce nuestras palabras en hechos en cuanto a una seguridad superior. Nos comprometemos a evitar que el 100 % de todos los programas maliciosos/virus conocidos se filtren en nuestra plataforma. Por cada pérdida, obtendrá cierta cantidad de crédito.
Otros proveedores toman atajos en sus acuerdos de nivel de servicio limitándose a pasar por el tráfico "conocido como seguro", como las redes de distribución de contenidos (CDN) y los servicios de intercambio de archivos, sin ningún tipo de análisis debido a los límites de arquitectura, escalabilidad o resistencia. Esta forma de pensar se está volviendo cada vez más anticuada en nuestro cambiante panorama de amenazas, ya que las amenazas entregadas a través de fuentes confiables y reputadas siguen aumentando.
Idea para reflexionar:
¿Está dispuesto a considerar todo el tráfico de las CDN, los proveedores de nube pública o los servicios de intercambio de archivos como de confianza?
3. SLA de baja latencia de proxy (velocidad ultrarrápida) -
La inspección del tráfico cifrado (sin límites) y la aplicación de motores de prevención de amenazas y pérdida de datos consume simultáneamente ciclos de CPU, es cuestión de física. Aquí es donde nos comprometemos a ofrecer seguridad y protección de datos extremadamente eficaces y eficientes con una experiencia de usuario superior.
Profundizamos en el SLA de latencia de proxy
Al optimizar la experiencia del usuario, debe tener en cuenta tanto la latencia de la red como la latencia del proxy. La optimización de la latencia de la red es un tema para otro blog, pero brevemente, la latencia de la red es el tiempo entre el cliente y Zscaler más el tiempo entre Zscaler y el servidor. Tanto la latencia de la red como la del proxy están muy optimizadas gracias a nuestra amplia presencia en el perímetro del servicio y a la capacidad de intercambio de pares. Sin embargo, esta sección se centra en la latencia del proxy:

La latencia del proxy es una métrica de capa 7 que refleja el tiempo añadido (en milisegundos) introducido por el proxy para analizar la solicitud HTTP/S, además del tiempo añadido para analizar la respuesta HTTP/S. En el diagrama anterior, la latencia del proxy es Xms (solicitud) + Yms (respuesta). Como proxy de capa 7, Zscaler ejecuta numerosos motores de seguridad y protección de datos tanto en las cabeceras de solicitud/carga útil como en las cabeceras de respuesta/carga útil, por lo que es importante capturar ambos lados.
¿Se puede eliminar la latencia del proxy ? No. Es cuestión de física; el análisis de cada transacción requiere ciclos de CPU. ¿Se puede optimizar la latencia de proxy? Sí, y lo analizaremos brevemente más adelante en el blog.
La manera correcta de ofrecer SLA de latencia de proxy líder en el sector
Lamentablemente, otros proveedores son famosos por su creativa letra pequeña para las exclusiones de SLA que malogran el propósito del mismo. Asegúrese de entender qué es exactamente lo que excluye un proveedor, cómo calcula su latencia y que no parezca demasiado bueno como para ser verdad.
1. Incluir análisis de amenazas y DLP
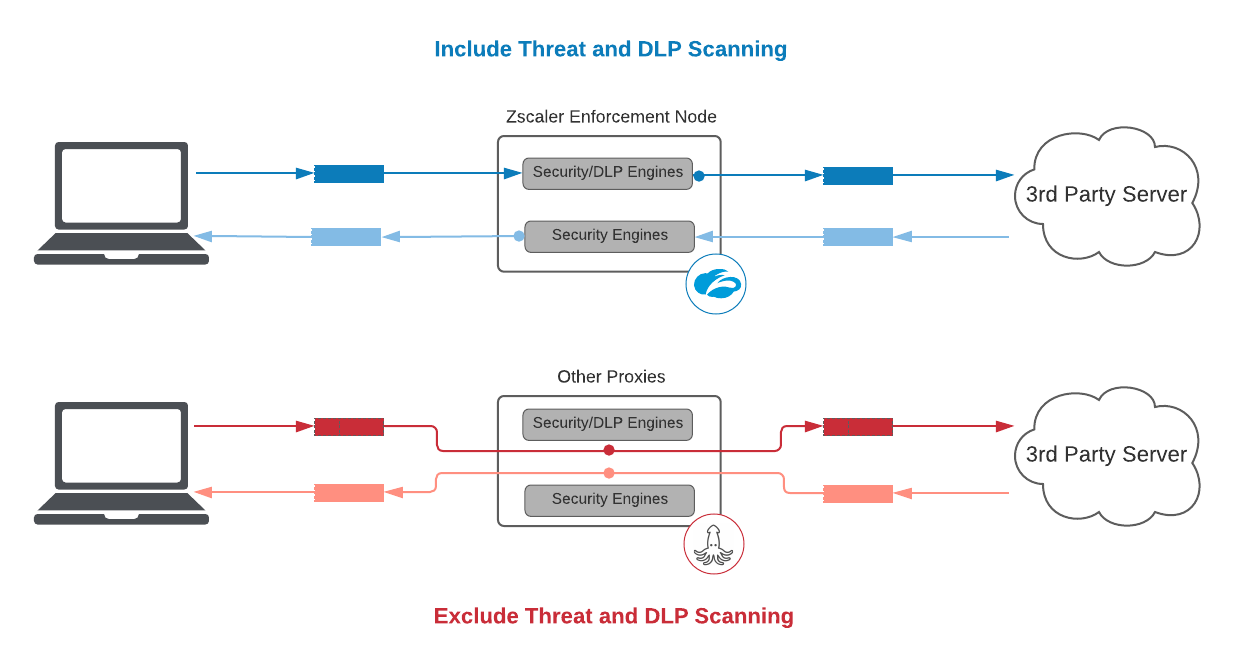
Como servicio de seguridad, excluir el análisis de amenazas y DLP frustra el objetivo del SLA.
Pasar paquetes de un lado a otro sin hacer ningún trabajo es "fácil". Tenga cuidado cuando los proveedores ofrezcan cifras de latencia que parezcan demasiado buenas para ser verdaderas. De hecho, si Zscaler quisiera ofrecer un SLA sin análisis de amenazas ni DLP, podríamos ofrecer un acuerdo de 25 ms y 5 ms para el percentil 95 para transacciones HTTPS descifradas y para transacciones HTTP de texto sin formato, respectivamente, 2 veces mejor que otros proveedores, pero creemos que no es una medida relevante y que sería altamente engañosa para nuestros clientes.
Por ejemplo, un proveedor de productos puntuales CASB, no creado para el procesamiento de tráfico en línea, muestra su verdadera cara en la letra pequeña:

Un SLA de latencia de proxy no debe excluir el tiempo añadido introducido por sus motores.
2. Proporcionar transparencia
Hay que demostrar las cosas con hechos: confíe, pero verifique todas las afirmaciones sobre latencia de su proveedor de seguridad en la nube.
Un SLA de latencia de proxy debe complementarse con informes proporcionados por el proveedor y métricas a nivel de transacción para que el proveedor rinda cuentas. Sin datos = sin SLA.
El detalle a nivel de transacción es la prueba real del impacto de la latencia y es fundamental para la transparencia y para la resolución de problemas. La combinación de una mala elección de la arquitectura con unos acuerdos de nivel de servicio agresivos pone a otros proveedores en una situación difícil para cumplir este requisito:
- Los proveedores de productos puntuales CASB se ven obligados a expandirse a nuevos mercados: al depender de un proyecto de proxy de código abierto no escalable, no existe un plano de registro de nivel empresarial que pueda capturar los registros a nivel de transacción (la gente de SOC que esté leyendo esto que lo asimile). No se puede informar de los SLA a nivel de transacción con este enfoque aunque se quiera... y punto.
- Proveedores de hardware heredados que intentan mantenerse relevantes: el servicio que encadena varias funciones con máquinas virtuales de cortafuegos en IaaS da como resultado cifras de latencia desglosadas y la incapacidad de reportar latencia de proxy de extremo a extremo en tiempo real.
As a result of either the inability or unwillingness to provide transparency, a known CASB vendor has been forced to use sneaky tactics to mask latency problems behind an hourly average. Since they can’t log at the transaction level, the average would be artificially skewed down during high variability hours.
Zscaler fue creado pensando en la transparencia. Estamos dispuestos y podemos proporcionar a nuestros clientes la visibilidad que les debemos:
Informe de latencia de revisión trimestral (QBR) proporcionado por Zscaler

Web Insights Log Viewer de Zscaler con visibilidad de la latencia del proxy a nivel de transacción
3. Centrarse en la latencia de las transacciones del proxy frente a la latencia de los paquetes del cortafuegos
La latencia del paquete representa una imagen incompleta de la latencia, especialmente en nuestro mundo centrado en la web.
Dado que estamos hablando de latencia de proxy, no me extenderé mucho, pero es importante entender la diferencia fundamental. La latencia del paquete es una medida del tiempo que tarda un dispositivo de cortafuegos físico o virtual en procesar los paquetes de solicitud (entrada a tiempo de salida); sin embargo, esta métrica es defectuosa. Medir el tiempo de procesamiento de la solicitud es solo una fracción de la latencia general de la transacción y se pierde el aspecto más importante de la latencia, la devolución de la información. Por naturaleza, la mayor parte del tráfico web son GET con pequeñas cargas útiles, pero grandes respuestas; esto es un grave malentendido de cómo debe medirse la latencia en nuestro mundo centrado en la web.
El ingrediente secreto de Zscaler para la mejor baja latencia de proxy de su clase
Escalar la infraestructura de la nube es el primer paso, pero la solución óptima se basa en una arquitectura subyacente adecuada. Zscaler analiza cada paquete y lo hace de forma extremadamente eficiente con servicios de seguridad paralelos llamados Single Scan, Multi-Action (SSMA):
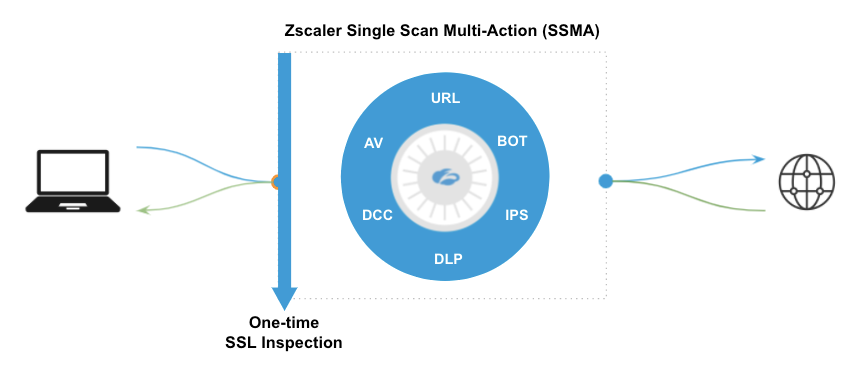
Máquinas Single Scan, Multi-Action de Zscaler que trabajan en paralelo
SSMA representa lo mejor de lo que los profesionales de la seguridad llevan décadas pidiendo al sector: una única plataforma que equilibra la mejor seguridad de su clase y una experiencia de usuario rápida. Esto es lo que Gartner llama "inspección de un solo paso del tráfico cifrado y el contenido a la velocidad de la línea" en el marco de SASE.
Con las arquitecturas heredadas, ya sean dispositivos de encadenamiento de servicios, servicios basados en la nube o una mezcla de ambos, los paquetes tienen que salir de la memoria de una máquina virtual (VM) a otra VM en un centro de datos diferente o en una nube completamente distinta. No hace falta ser un experto en física o en redes para ver que esto resulta ineficiente y tremendamente complejo.
Zscaler fue construido con una arquitectura nativa de la nube que coloca los paquetes en la memoria compartida en servidores altamente optimizados y construidos a propósito, diseñados para una ruta de datos optimizada. Aún más importante es que todas las CPU de un nodo Zscaler pueden acceder a esos paquetes al mismo tiempo. Al tener CPU dedicadas para cada función, todos los motores pueden inspeccionar los mismos paquetes al mismo tiempo (de ahí el nombre, Single Scan, Multi-Action). Esto garantiza que no haya latencia añadida por el encadenamiento de servicios, lo que permite al nodo Zscaler tomar decisiones de política con extrema rapidez y reenviar los paquetes a Internet.
En resumen, la reutilización de dispositivos virtuales heredados y de proyectos proxy de código abierto de etiqueta blanca con motores vinculados no funciona. Hay demasiada deuda técnica heredada que abordar y compensar al adoptar estos enfoques.
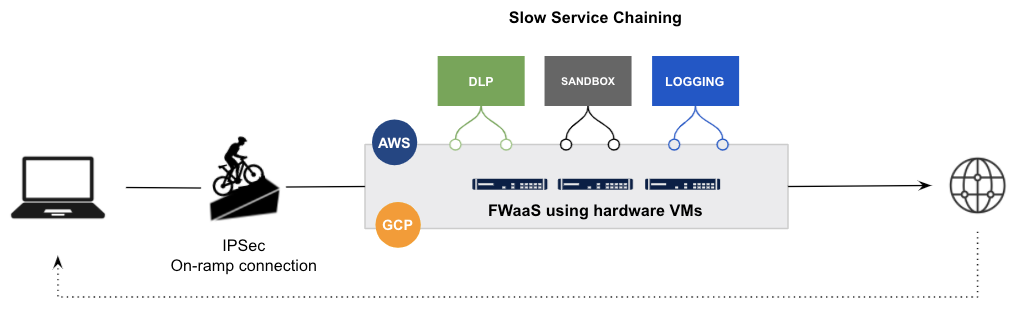
Ejemplo de un proveedor heredado que reutiliza máquinas virtuales de FW heredadas en IaaS con encadenamiento de servicios
Asegúrese de que sus proveedores sean honestos sobre sus SLA
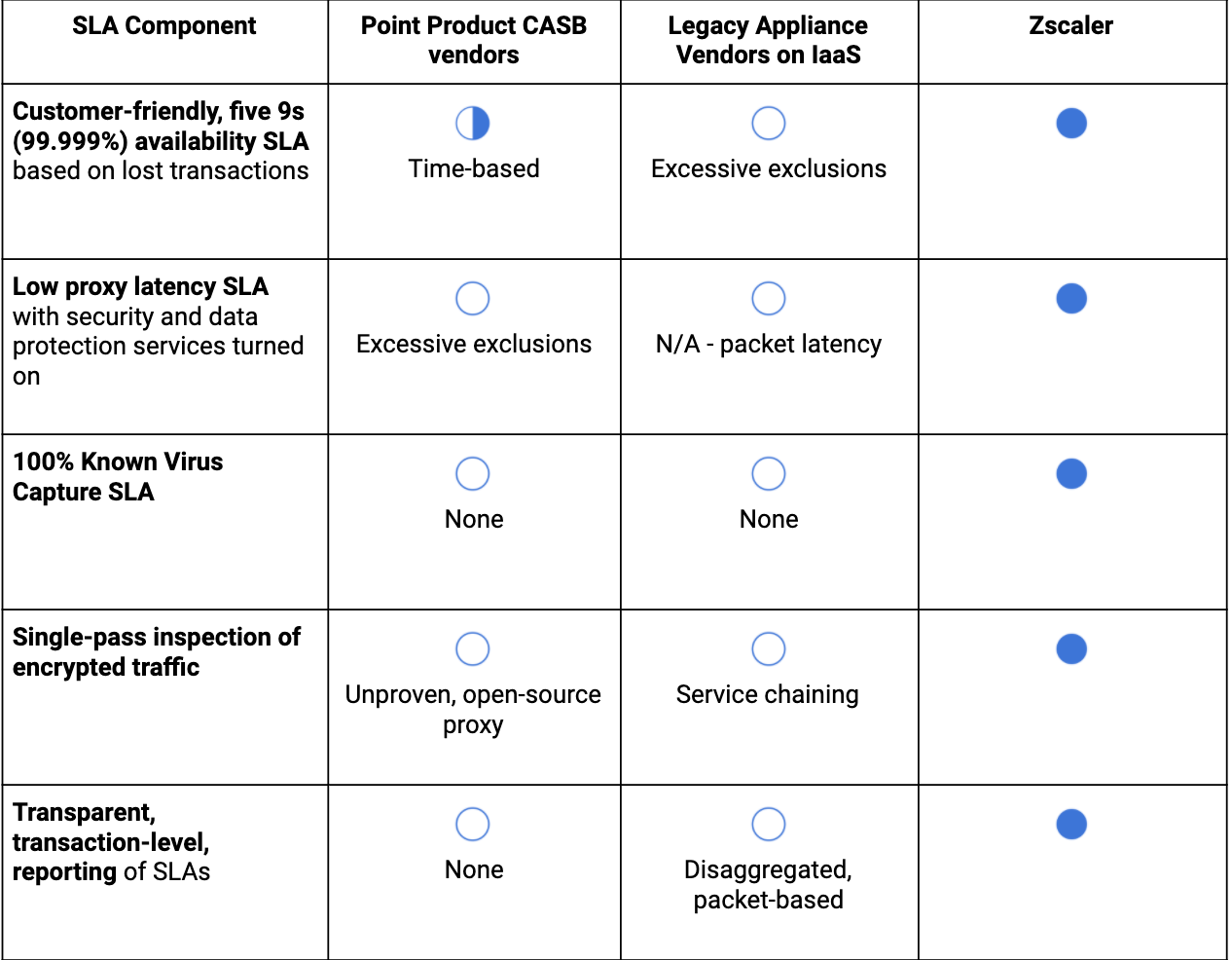
Le doy un consejo sobre cómo poner en práctica esta información. Muchos de nuestros clientes y futuros clientes centran sus conversaciones sobre los SLA con los proveedores en torno a la disponibilidad, que es una cuestión ciertamente importante, pero que deja lagunas en el análisis del servicio de un proveedor.
A continuación tiene una tabla rápida que puede utilizar para identificar los componentes clave de los acuerdos de nivel de servicio que se le mostrarán:

¿Este post ha sido útil?
Exención de responsabilidad: Este blog post ha sido creado por Zscaler con fines informativos exclusivamente y se ofrece "como es" sin ninguna garantía de precisión, integridad o fiabilidad. Zscaler no asume responsabilidad alguna por cualesquiera errores u omisiones ni por ninguna acción emprendida en base a la información suministrada. Cualesquiera sitios web de terceros o recursos vinculados a este blog se suministran exclusivamente por conveniencia y Zscaler no se hace responsable de su contenido o sus prácticas. Todo el contenido es susceptible a cambio sin previo aviso. Al acceder a este blog, usted acepta estas condiciones y reconoce su responsabilidad exclusiva de verificar y utilizar la información según sea precisa para sus necesidades.
Explorar más blogs de Zscaler

Agniane Stealer: Dark Web’s Crypto Threat

The Impact of the SEC’s New Cybersecurity Policies

Security Advisory: Remote Code Execution Vulnerability (CVE-2023-3519)

The TOITOIN Trojan: Analyzing a New Multi-Stage Attack Targeting LATAM Region
Reciba en su bandeja de entrada las últimas actualizaciones del blog de Zscaler
Al enviar el formulario, acepta nuestra política de privacidad.